

Digitizing Invoices at Scale using AWS Step Function and SQS Queue
by Rupesh Mishra
At Ottimate we process over a million invoices every month, amounting to more than $1 billion in transactional volume for our customers.
At this scale it is critical for us to build technology and infrastructure that can process large volume of invoices reliably with a very high SLA.
Here’s how we do it
We provide different methods for our customers to upload invoices into Ottimate. Customers can take pictures of invoices and upload them via our mobile app, they can email or drag and drop scanned images of invoices and they can also connect their suppliers directly with Ottimate via EDI (Electronic Data Interchange)
EDI offers a fast and reliable mechanism for our customers to automate their invoice processing. Once an EDI is configured Ottimate will automatically process invoices from the supplier immediately without requiring any manual intervention
We have built EDI integrations with more than 100+ suppliers that include Sysco, US Foods, Aramark, etc and support industry standards such as 810.
In this article we describe the technology that powers our EDI integration, and our ability to scale towards processing large volume of EDI invoices reliably with a very high SLA
Representation of Files at PlateIQ
The files that we get from various incoming sources are represented as Container in the Ottimate system. Each of these files contains one or multiple invoices. And so, the Container holds all the invoices from the input file. Our goal is to digitize these invoices and export them to the accounting software of the customers. This helps in getting rid of the manual data entry of the invoices in the system.
Digitization is the process of reading the text from the files and storing the data in a meaningful format!
We use machine learning models for digitizing the invoice files in PDF and JPEG format while we use parsers for digitizing the files in JSON, CSV, EDI (Electronic Data Interchange) formats. The parser parses each of the incoming invoice files and creates invoice objects for them in the PlateIQ system. And the interesting part is how we populate these objects and store them in the datastore to make sense of this data! Let’s get going!
Let’s understand the digitization process followed to digitize EDI invoices. In this process we use AWS Event Bridge, Batch Jobs and AWS Step function
Digitization using AWS Event Bridge, Batch Jobs and Step Function
The AWS Event Bridge and Rules are used to run the batch jobs periodically. The batch jobs are responsible for getting the files from the incoming sources (FTP, Websites, Email).
Here’s the simplified architecture for the processing of the file:
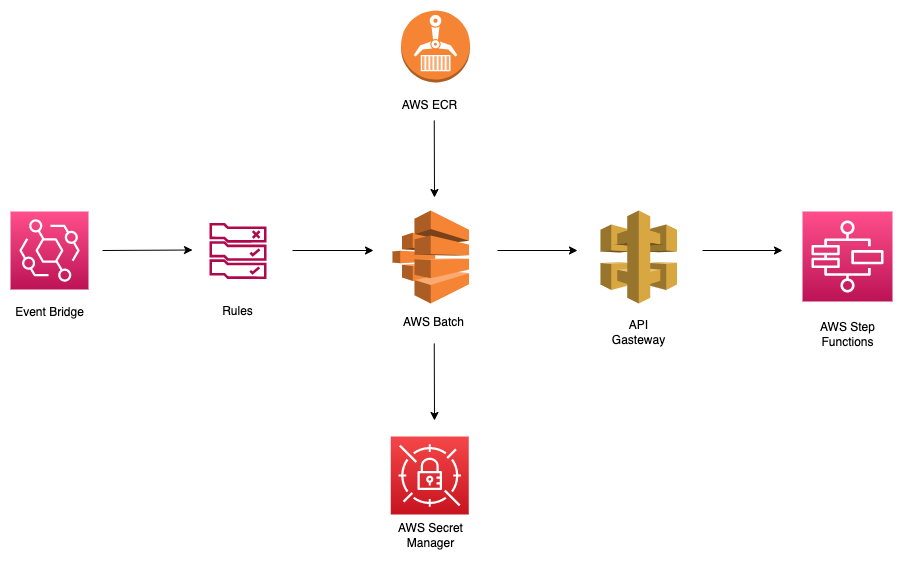
The Docker image from AWS ECR is used to define the batch job. As seen in the above diagram, AWS Batch Jobs fetch the secret from AWS Secret Manager and polls a number of FTP servers to get the files for processing.
It then creates a Container for each of these files. Once a Container is created, it makes an API call (defined using the API Gateway) to trigger the execution of the AWS Step function for the created Container.
Now that the container is created in the system, we follow these steps in the AWS Step function:
- Update the state of the container from New to Processing
- Parse the incoming file to get the invoices
- Create invoices obtained in the previous step in the Ottimate system
- Verify if the number of invoices created in the Ottimate system is equal to the number of invoices obtained by parsing the input file.
We use the AWS Lambda function for executing each of these steps. These steps are sequential which means that we’ll have to coordinate among these lambda functions to make sure the succeeding step in the process is executed only after its preceding step is completed. We use the AWS Step function to establish this coordination in an efficient manner!
Here’s the representation of the step function:
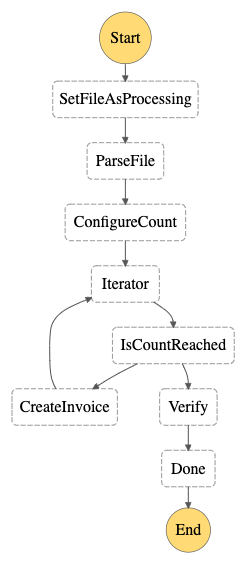
This diagram is only for representational purposes and doesn’t represent the actual system.
Let’s look at each of the steps in the Step function and understand what each of these steps do:
SetFileAsProcessing – In this step, we make an API call to change the state of the Container from New to Processing.
ParseFile – This step parses the file and gets all the invoices. A file can have multiple invoices and hence the output of the step will be a list of invoices.
Iterator and ConfigureCount steps are used to iterate over each invoice obtained from the ParseFile step.
CreateInvoice – This step is called for every invoice in the list. It makes an API call to create the invoice in the Ottimate system. Once all the invoices (output of the ParseFile step) are created, the Verify step is executed.
Verify – This step verifies if the above steps were executed successfully. It makes an API call to get the number of invoices created for a particular container and compares the number of invoices created in the system with the number of invoices that we got in the ParseFile step. If this count is verified, we make an API call to update the state of the Container from Processing to Done. If this count doesn’t match, we update the state of the Container from Processing to Error.
The current setup works fine for our use case when all the microservices that the step function is interacting with are working in the expected state. We make API calls in different steps to these microservices for updating the state of the container, creating invoices, verifying the count and updating the final state of the container in the last step. While we are in the middle of the container processing and are not able to reach one of the microservices, the current container processing would fail and we’ll have to run the step function again for this particular container.
Imagine a case where there are 50 invoices in a Container and the step function failed at the last step while updating the state of the Container from Processing to Done. We’ll run the step function again for this container! This execution of the step function though would take lesser time compared to the earlier one as we’ll use the stored intermediary data.
The step function is tightly coupled with the microservices (responsible for updating the container state and creating invoices).
We wanted to remove this tight coupling of the AWS Step function with the microservices. We can achieve this by introducing SQS as an event source for the lambda function and implementing a service integration pattern for the AWS Step function. This might sound a bit complicated. Let’s try to first understand these:
- SQS as an Event Source for the Lambda function
- Service Integration Pattern in AWS Step function
AWS SQS as an Event Source for the Lambda function
Simple Queue Service(SQS) is a message queuing service provided by AWS. Here’s the definition on the AWS documentation:
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enabled you to decouple and scale microservices, distributed systems, and serverless applications.
We can configure SQS as an event source for the AWS lambda function. The lambda functions would be invoked automatically when the message arrives in the queue.
Please note that the lambda functions are not invoked by the SQS queue. They are invoked by the event source mapping. An event source mapping is basically a Lambda resource that reads the message from the SQS queue and then invokes the lambda function synchronously using an event that contains the queue message.
The event source mapping reads messages in batches from the SQS queue. The size of a batch is a configurable parameter and can be changed as per the requirement. The event source mapping invokes an instance of a Lambda function for each batch. For example, it would read messages for different containers in a batch and then invokes the lambda function.
The structure of the AWS SQS message as an event inside the Lambda function is as shown below:

Let’s understand the fields in the above JSON:
Records is the list of messages in the SQS queue. Each element in this list contains the actual message along with some extra information like md5OfBody, messageId etc. The actual message is present in the body property. In the above example, Hello, World is an actual message from the SQS queue.
The event source mapping fetches the messages from the SQS queue in batches and hence the number of elements in the Records list would be more than one.
The event source mapping deletes the batch of messages from the SQS queue once the lambda function successfully processes the entire batch. If the processing of any message in the batch fails, the whole batch would be processed again! The event source mapping scales as per the number of messages in the queue.
Also, if the processing of any message in a batch fails due to some reason, the lambda function will try to process that message again. In case the message is invalid which means the processing would always fail for this particular message, then the Lambda function would process this message until the retention period is expired for this message.
Example of SQS as an Event Source for a Lambda function
Let’s understand more with the help of an example of SQS as an event source for a lambda function!
We’ll define a lambda function add_numbers and a SQS queue number_q. The add_numbers function gets an event with a batch of messages from the SQS queue. Here’s how a message in a queue looks like:

Here’s the add_numbers lambda function:

Creating the add_numbers lambda function
Creating the number_q SQS queue
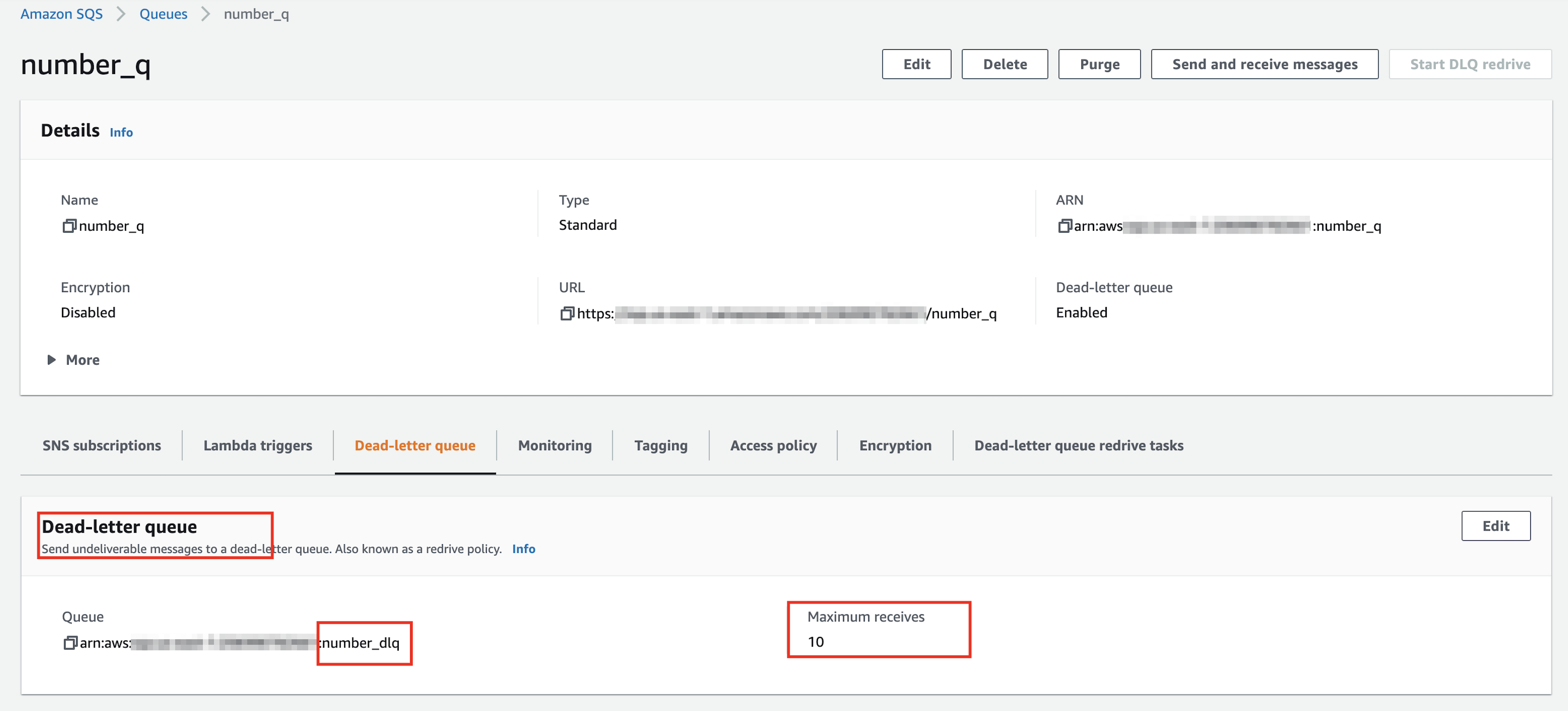
The number_q queue is created successfully! In the above screenshot, there is one dead letter queue called number_dlq. The value of the Maximum Receives field is 10 in the above screenshot which means that the message would be re-processed 10 times if it fails. It would be moved to the dead letter queue after retrying 10 times.
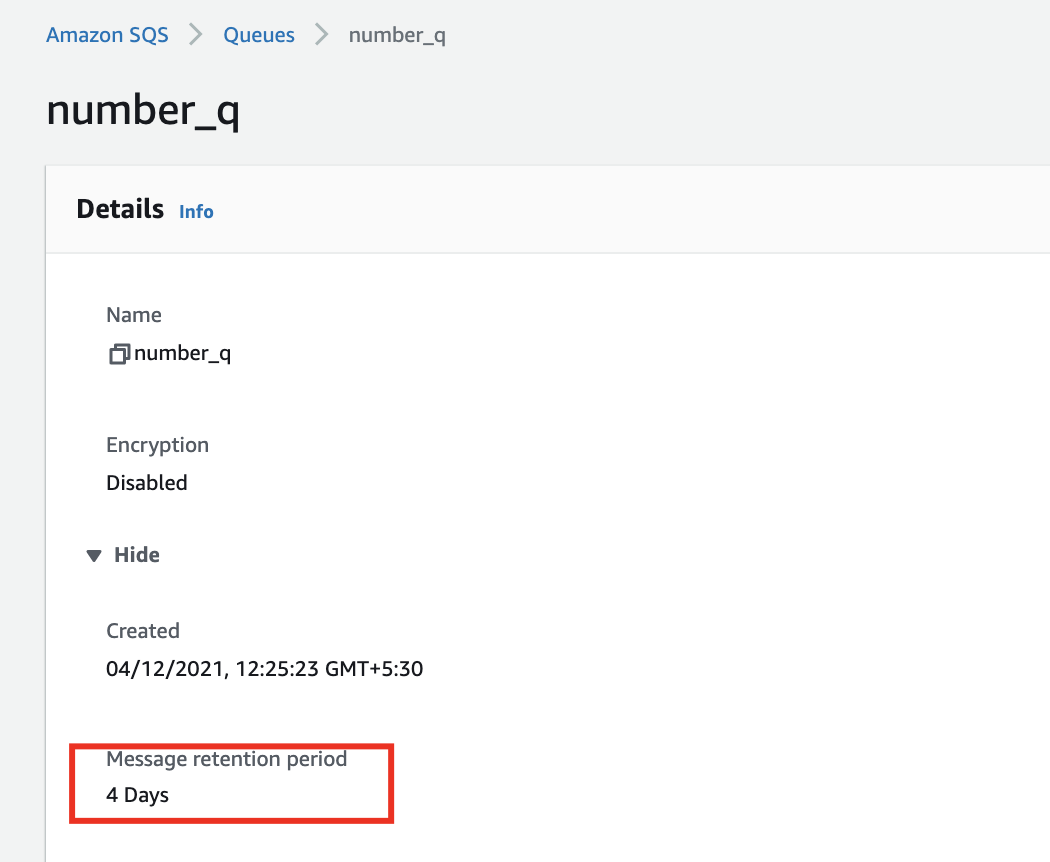
As seen in the above screenshot, the retention period for number_q is 4 days. The messages would be deleted automatically from the queue after 4 days.
Adding event source for the lambda function
Let’s now add number_q as an event source for the lambda function add_number:
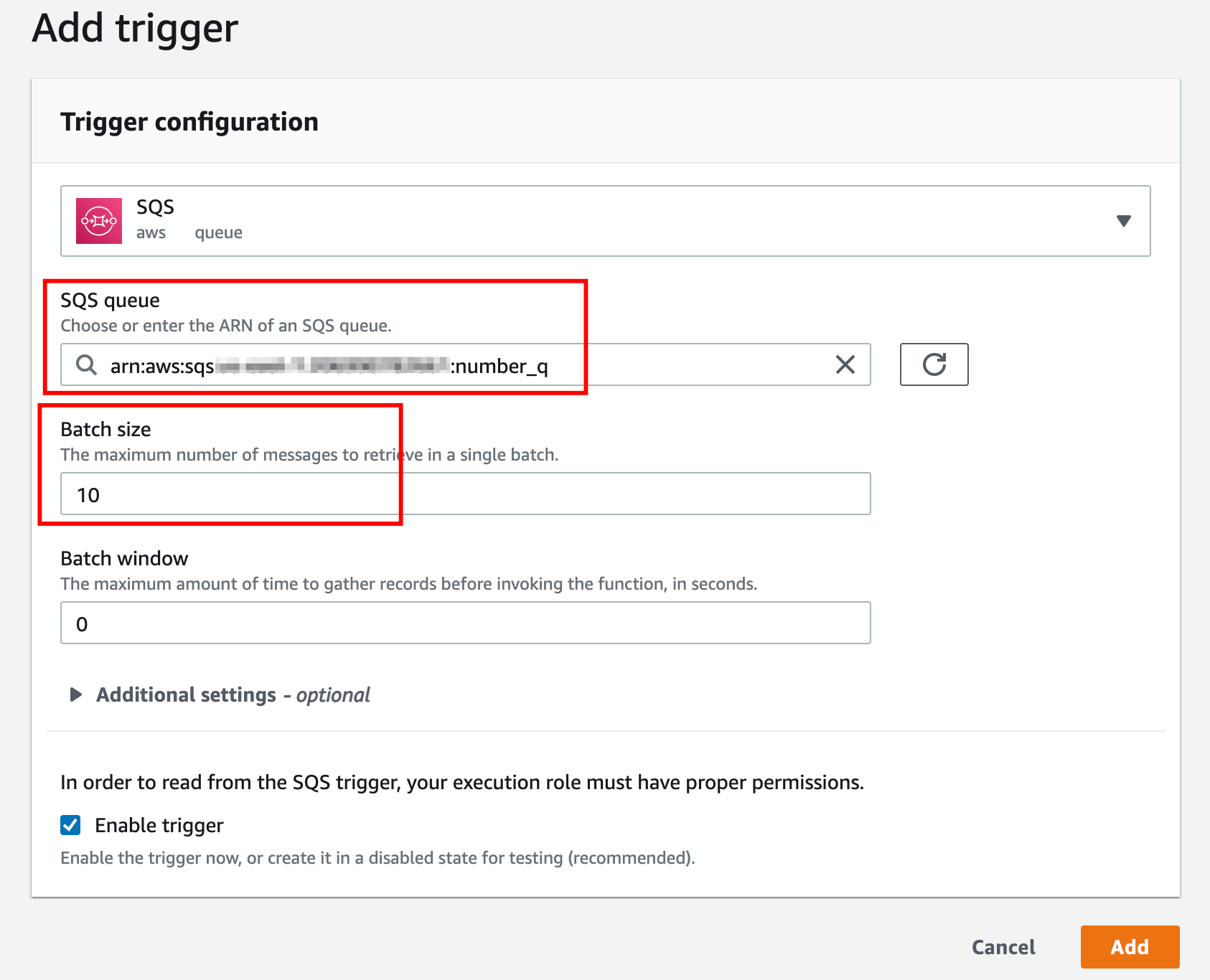
While adding the SQS queue as an event source for the lambda function, we can also specify the batch size as shown above in the screenshot. The default batch size is 10.
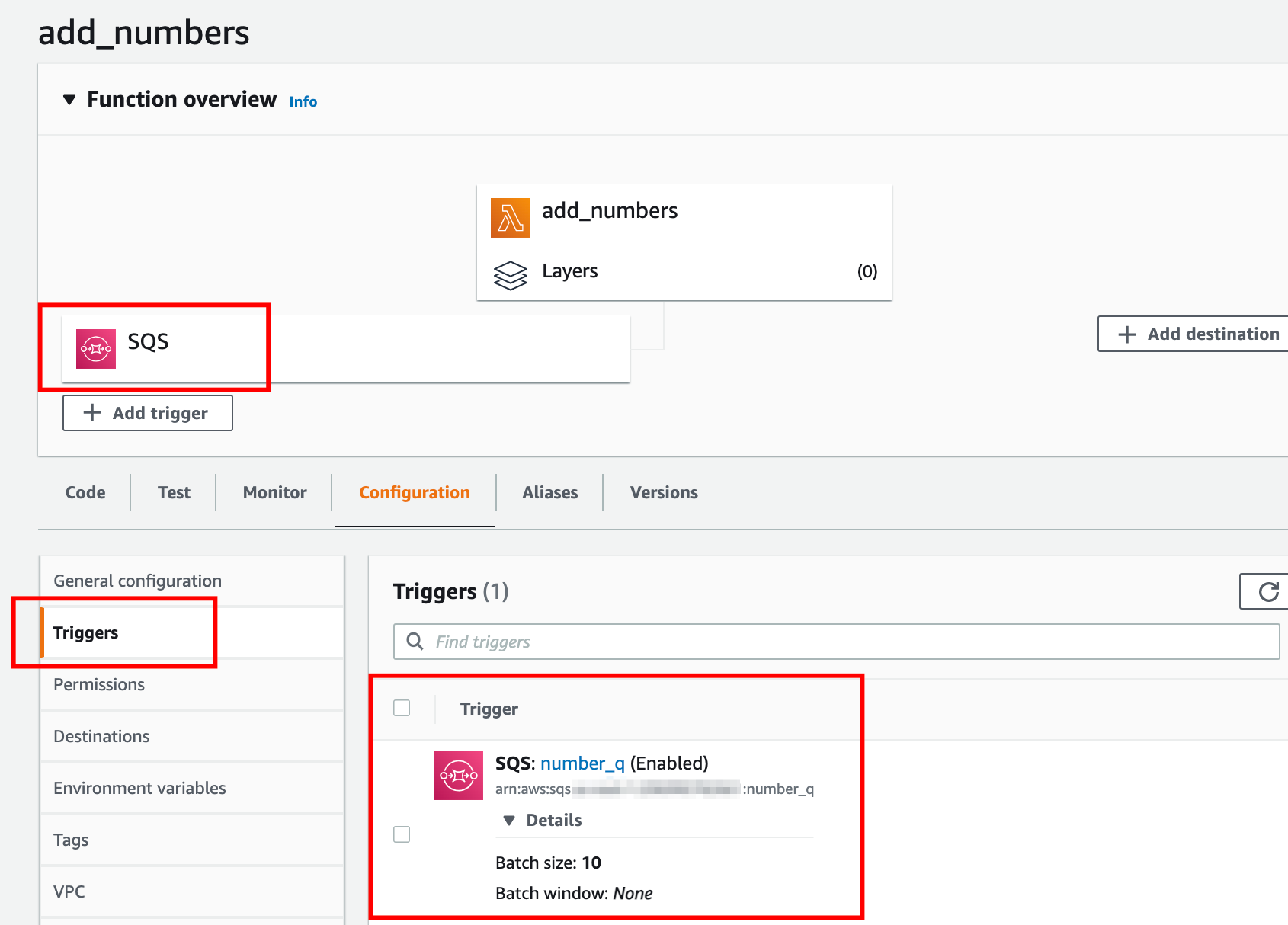
Perfect! We can see that the number_q queue is added as an event source for the lambda function add_numbers. Whenever any message arrives in the number_q queue, the add_numbers lambda function is invoked automatically.
Service Integrations Pattern
The AWS step function provides Service Integration Patterns that can be used to integrate step functions with the other AWS services such as SQS, Batch Jobs.
We have to define a state with type Task to integrate the AWS step function with the SQS queue. Here’s how to do that!

In the above snippet, the Resource field of the state definition contains .waitForTaskToken which tells the step function to pause at this state and wait for the task token. Please note that the task token is generated automatically by the step function in the first step.
The step function pauses on this step until it receives the task token back with a SendTaskSucsess or SendTaskFailure call.
The MessageBody field contains the message to put in the SQS queue. It also contains the task token in the TaskToken field. The SQS queue is defined by the QueueUrl field.
The SQS consumer (AWS lambda function in this case) will process the message in the queue and would send Success or Failure with the task token using SendTaskSuccess or SendTaskFailure calls respectively. Once the step function receives the SendTaskSuccess call it will continue and execute the next step.
If the step function receives the task token with SendTaskFailure call in some particular step, that step would be failed and the lambda function would try again!
Savings on AWS costs with Service Integration Pattern
We don’t have to poll the queue with Service Integration Pattern in place. We get sendTaskSuccess or sendTaskFailure message to invoke the step function and begin execution. When there is no message, the step function goes to the pause state and we’re not charged while the step function is in pause state. This helps in saving on the AWS costs.
Now that we have understood the Service Integration Pattern and how the SQS queue acts as an event source for the lambda function, let’s look at the updated workflow that would help in decoupling the step function from the microservices!
Decoupling the Step Function from the Microservices
We have integrated the step function with the SQS queue using the Service Integration Pattern for decoupling this step function from the microservices. This queue acts as an event source for the lambda function and is responsible for making the API calls.
Here’s the definition of the step function:


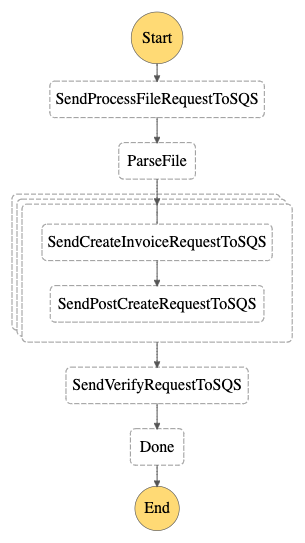
And, here is the workflow diagram for the above step function:
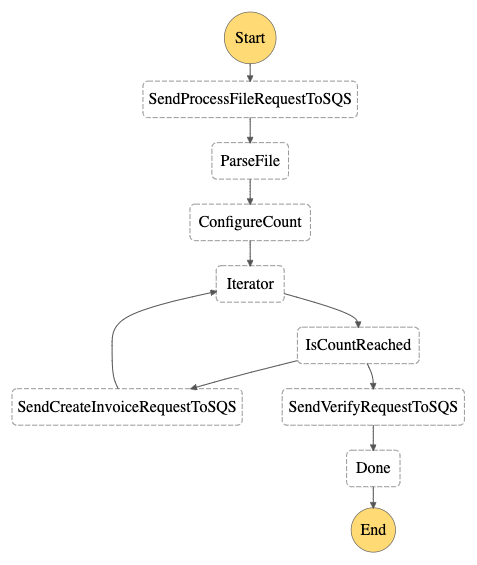
In this step function, we’re integrating the SQS queue with the step function using .waitForTaskToken. The step function puts the message in the queue and waits until it gets the task token back from the SQS consumer.
Each of the SQS queues acts as an event source for the Lambda functions.
The lambda function attached to a particular SQS queue has the responsibility to make the API call. For example, in the state SendProcessFileRequestToSQS, the step function just puts the message (along with the task token) in the SQS queue (process-file) and goes into the pause state.
The process-file SQS queue acts as a source for the Lambda function set_file_state. When the message arrives in the queue, the set_file_state lambda function is triggered and it makes an API call to update the status of the file (container in the database) to processing.
If this API call is successful, the lambda function calls SendTaskSuccess with the task token, and step function resumes and it moves to the next state ParseFile.
Let’s say for some time the microservice is down! In this case, the message is put back in the SQS queue after the visibility time period expires and the lambda function will try to process this message again. It will try processing the message multiple times until the retry count is greater than the Max Receives count. If the message is not yet processed, it would be moved to the dead letter queue.
The lambda function handle_dead_letter_queue calls SendTaskFailure with the task token and the step function fails.
In this way, we are able to successfully parse larger invoices asynchronously and have built the retry mechanism for intermittent/unexpected failures on the microservices front! We get almost no errors after remodelling the workflow this way!
We also did some optimizations in this workflow to have a scalable and robust system. Let’s look at these optimizations:
Creating Invoices Parallely
So far, we have been creating the invoices one by one using the Iterator lambda function. This can lead to a significant delay in creating a larger number of invoices. We replaced the Iterator lambda function with the Map state of the step function.
Map State of the Step Function
The Map state of the step function is used to run a set of steps for the input. It accepts the input as a list of elements and for each element in the list, it executes all the steps defined in the Map state. It has the capability to process these items in the input list in parallel. Here’s the example definition of the Map State:

The ItemsPath field specifies the list of items on which we want to run the Map state.
The MaxConcurrency field indicates the maximum number of items that can be processed simultaneously.
Iterator.State defines all the steps of the Map state.
Each item from the ItemsPath array will go through each state of Iterator.State.
We can update the step function definition with the Map state as shown below:


Here’s the updated workflow:
Conclusion
In this article, we looked at the digitization process of files using AWS Event Bridge and Batch jobs and understood the dependency of the step function on microservices. We then learned about the AWS SQS queue as an event source for the lambda function, AWS Service Integration patterns and how we can leverage these two to build a scalable digitization system that is decoupled from the state of the microservices.
Stay up to date on the latest news in AP automation and finance
Related

