

How Invoice Processing & Machine Learning Work Together
by The Ottimate Editorial Team
Invoice processing and machine learning go hand-in-hand when it comes to automating your AP workflow. At Ottimate, we provide an invaluable service in helping our customers streamline their back-office and accounts payable operations by utilizing these tools.
Every day we process tens of thousands of invoices from restaurants all over the country so that their operations teams do not have to do such tedious work. Our customers rely on us to extract highly accurate data from invoices so that they can reduce manual processing, analyze their spending, and pay their bills on time. No one wants to spend extra time searching through invoices and balancing their books.

A fundamental problem in digitizing invoices is having to determine whether an invoice document is a debit, or if it is actually a credit.
Credit invoices by definition have a negative total amount. While this can make the problem sound trivial, it is quite difficult to automatically determine the invoice type with the high level of accuracy we seek to retain, for a variety of reasons:
- Invoices come in different layouts or formats. To complicate things further, some vendors have different internal layouts.
- Everyday we add hundreds of new vendors and layouts into our system. With that in mind, a pure template matching based method will not scale.
- Some vendors do not print the total amount as a negative even though it is a Credit, we need to infer that an invoice is indeed a Credit and not a Debit by interpreting the entire document.
- Vendors have different ways of representing negative values: Some use “-123.45”, while others use “(123.45)” or “123.45-”
- Vendors use different terms for their Credit invoices: Credit, Memo, Returns, Refund, etc ..
- Errors that occur in OCR text further compounds the above problems
We decided to solve this problem using deep learning. Let’s go into the details.
Invoice Processing & Machine Learning: Technical Introduction to the Problem
In this project, we are dealing with a two-class classification problem (Credit or Debit).
The first solution that might come to one’s mind is to check for the word “credit” in the invoice text. We can do something like this: If the word “credit” is in the invoice, predict the invoice as credit, otherwise debit. If we do that, we get the following confusion matrix in the test set. (In parentheses, we have values normalized by the number of samples in class.)

We can see that almost 20% of Debit invoices (18% to be exact) are confused with the Credit class. Given the large volume of invoices processed at Ottimate, that would create too many false positives not to mention the 21% of credit invoices that we are missing.
We can keep adding manual rules such as looking for the word “return”, or the location of the word “credit” in the invoice image, which might increase the accuracy. However, adding these heuristics is not scalable or feasible. As functionality and efficiency are at the core of our values we soon discovered that we can do much better with deep learning, especially due to the amount of training data we have available at Ottimate.
In the next sections, we will be covering how we handled this problem using Convolutional Neural Networks over text. Now let’s start with explaining the dataset we used for this problem.
Dataset Collection
For this project, we had sufficient data to train a model. However, the problem is class imbalance. There are much more Debit invoices than Credit invoices. We use class weights to account for this problem.
Train — Validation — Test Splitting
To properly test a machine learning model, we should have separate and isolated validation and test datasets. Train, Validation and Test splits are done with the following ratios: 0.7, 0.15, 0.15.
These splits are created by taking vendors into account. It means that no same vendor appears in different data splits. This is done to check how much the machine learning model is actually “learning” rather than “memorizing” a specific layout or structure of an invoice, since within the same vendor, invoices have pretty much the same layout.
Features
For features, we just obtain the text of the invoice documents. We will treat this text as a sequence of characters. The reason why we chose to treat this text as a sequence of characters, rather than a sequence of words is because the difference between a Debit invoice and a Credit invoice is often very subtle. In some cases the only difference is a minus sign in the total amount of the invoice. What’s more, the text obtained from OCR is not perfect. For instance, some characters in some words might be flipped. Therefore, approaching this problem in character level seems more reasonable.
For practical training purposes, we need to fix the length of these texts to a certain number. Because of the distribution of the lengths of these invoice texts, we chose this number to be 1500.
On that note, to fix the size, we don’t just chop or pad the last part of the text. Instead we insert some domain knowledge while fixing the text size. We assume that the strongest signals in determining whether an invoice is a Credit or Debit is either the “Credit Memo” text at the top of the invoice or the minus sign for the total amount at the bottom. Therefore, we either remove or pad the middle of the invoice text.
Model and Training
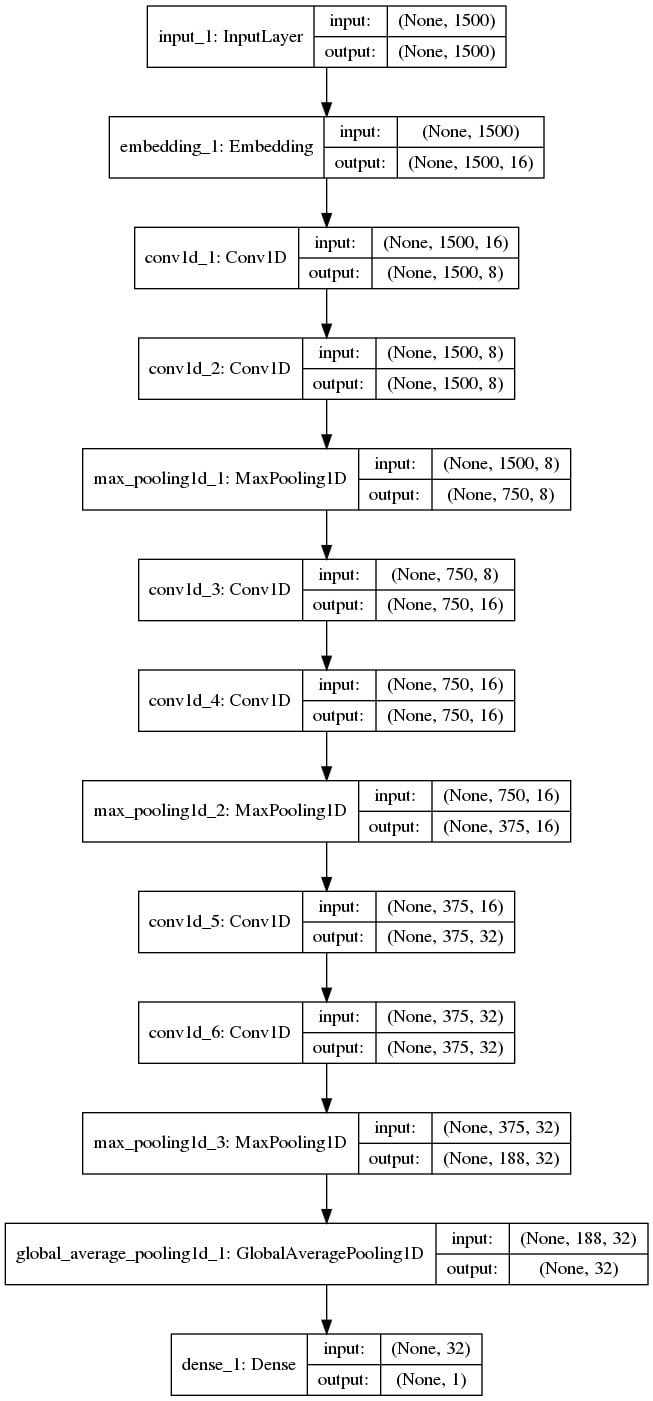
For this classification task we decided to use Convolutional Neural Networks (CNN).
In literature, we can find papers that approach text classification problems at character-level as we did here, such as [2], [3] and [4].
From [2],
“The most important conclusion from our experiments is that character-level ConvNets could work for text classification without the need for words. This is a strong indication that language could also be thought of as a signal no different from any other kind.”
On the left, you can see the architecture of the network. We first do one-hot encoding of the characters in the invoice text and use an embedding layer as the first layer. The rest of the network resembles a smaller version of VGG16 model, but with one-dimensional convolutional layers, since text is a one-dimensional signal. An important thing here to notice is the Global Average Pooling (GAP) layer towards the end of this network. The GAP layer acts as a structural regularization [1]. It also helps us to obtain Class Activation Maps, which we will cover in the next sections.
The loss function is binary cross entropy, the optimizer is Adam.
Results
After training the model, we get the following results in the test set.

Results on the test set look much better than what we started with (simply checking whether the word “credit” is in invoice text or not.)
Character Embeddings
After the training is done, it’s useful to take a look at the learned weights of the model and try to understand what our model discovered. For this purpose, we can look at the weights of our embedding layer. These weights will correspond to the embeddings of each character. Let’s do dimensionality reduction on these character embeddings and visualize:
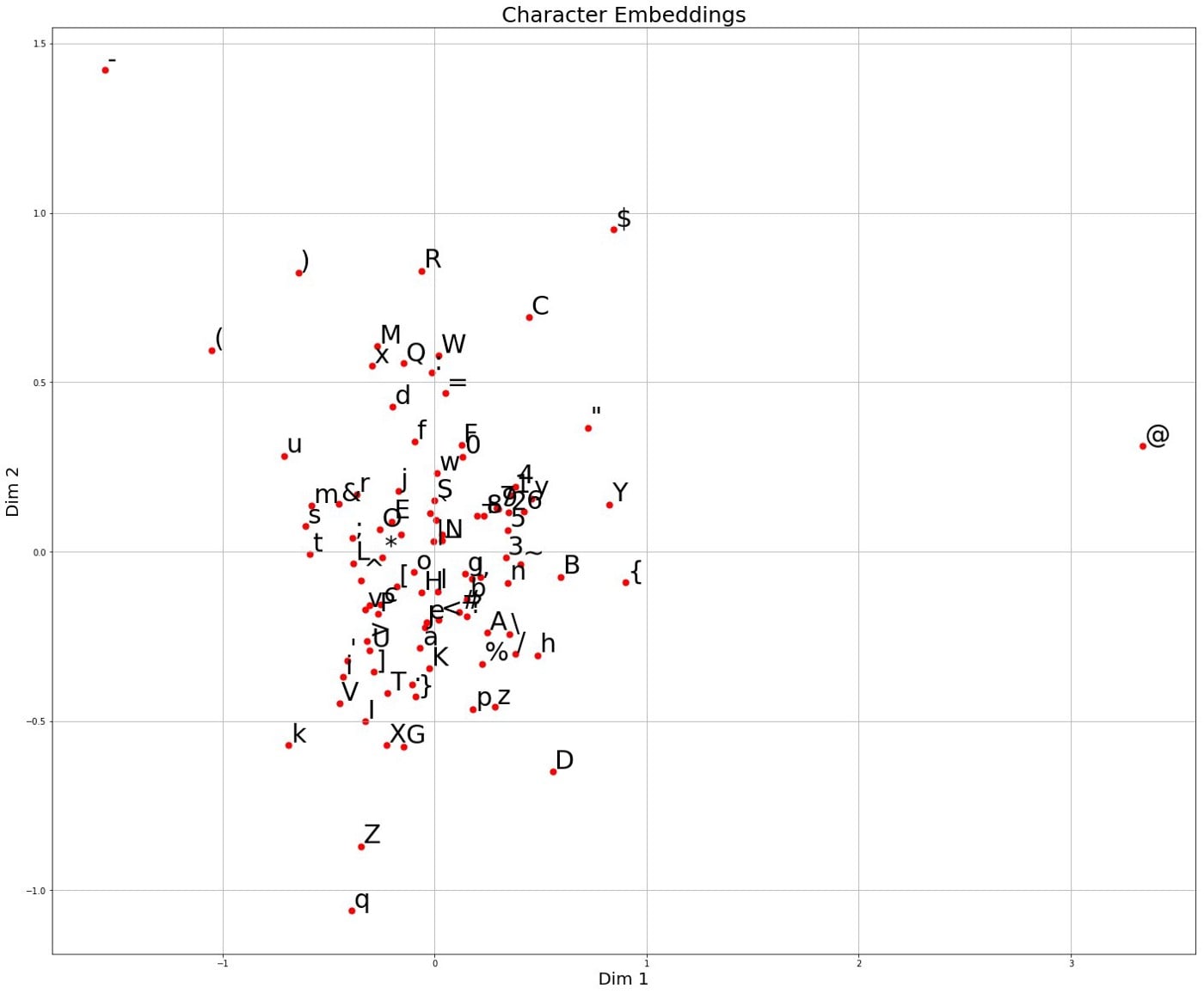
Above, there is something to observe. These three characters (minus sign, left parenthesis, right parenthesis) –, (, and ) stay apart from the rest of the characters (They are towards top-left). These characters are usually at the total amount of the invoice and they are strong indications that the invoice is a Credit. Below, you can see some examples:
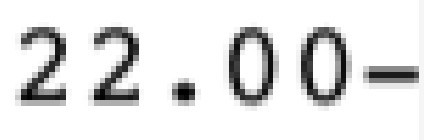
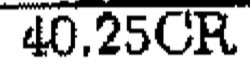

Our intuition behind this is that the network must have figured out that these characters play an important role for the discrimination between Debit and Credit invoices.
Visualizing Class Activations
In this section, we will try to shine some light on the inner workings of our CNN model. By looking at the feature maps in the Global Average Pooling layer, we can see where the model is paying attention to make a decision. Here are some results
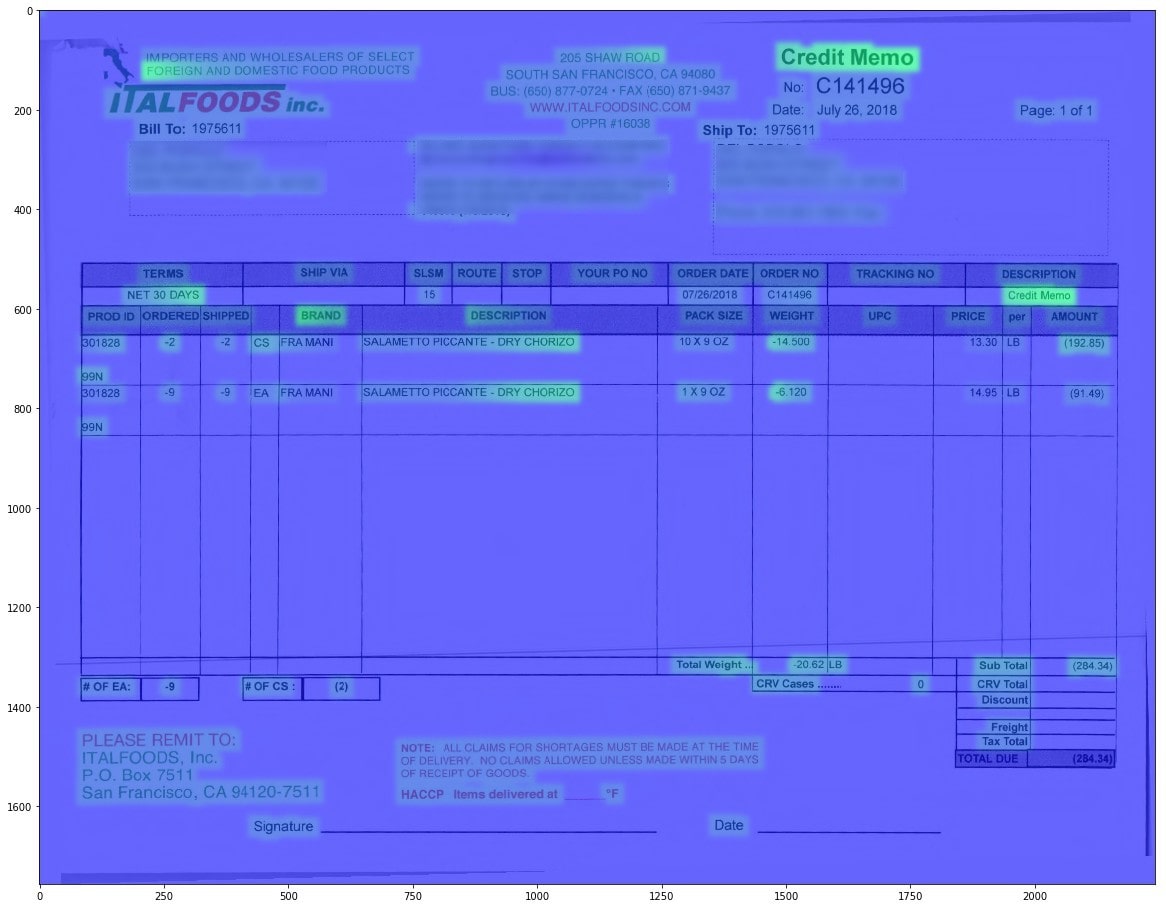


To obtain these results, we implemented the simple technique in [1]. The only difference is, in the paper, this is applied to images. However, this technique can easily be transferred to one-dimensional data, which is text.
When we forward-pass an invoice text, we get feature maps from the last convolutional layer. Since our task is to classify credit/debit, the neurons must be sensitive to things that signal that an invoice is Credit, as a result the neurons are firing at specific locations indicating that the invoice is a Credit. At the end of our model, we have a single neuron with a sigmoid activation function. The weights of this neuron are the “importance” of each feature map, therefore we scale each feature map with its corresponding weight and take the average. This is the Class Activation Map (CAM).
We obtain the characters of an invoice with an OCR Engine. As a result we know the location of each character in the image. After obtaining the one-dimensional CAM, we can map it back the original invoice image.
It is very interesting to see that we can get localization results from a model that was only trained for classification purposes.
Invoice Processing & Machine Learning: Final Results
As we have been using the Deep Learning model in our invoice digitization platform, we have seen a significant improvement (> 25%) in both precision and recall. This has had a direct, and positive impact on our overall data quality and customer satisfaction metrics.
While we are happy with our current model, we think we can improve the performance by using sampling and ensembling strategies. These, we believe will better handle the class imbalance problem. We will talk about our progress on this problem and other exciting machine learning projects at Ottimate in our future blog posts.
Interested in seeing how Ottimate can streamline your AP process? Request a demo today!
References
[1] Learning Deep Features for Discriminative Localization: https://arxiv.org/pdf/1512.04150.pdf [2] Text Understanding from Scratch https://arxiv.org/pdf/1502.01710.pdf [3] Character-level Convolutional Networks for Text Classification https://arxiv.org/pdf/1509.01626.pdf [4] Very Deep Convolutional Networks for Text Classification https://arxiv.org/pdf/1606.01781.pdf
Stay up to date on the latest news in AP automation and finance
Related

